Syllable Walker Web
Overview
Pipe-Works Build Tools — Web Application
Combined web interface for the Pipeline and Walker build tools,
providing a browser-based alternative to pipeline_tui and
syllable_walk_tui.
This is a build-time tool only — not used during runtime name generation.
- Features:
Pipeline tool: extraction, normalization, annotation with live monitoring
Walker tool: dual-patch syllable walking, name combiner, name selector
Corpus analysis with terrain visualization and profile reach deep-dives
Name rendering and package export (ZIP with manifest + disk metadata persistence)
Dark/light theme support
18 API endpoints across Pipeline, Walker, Browse, Settings, and Version groups
- Architecture:
api/: Request handlers (browse,pipeline,walker)services/: Business logic (corpus_loader,combiner_runner,selector_runner,walk_generator,metrics,packager,pipeline_runner)state.py: Dataclasses (PatchState,PipelineJobState,ServerState)server.py: stdlibhttp.serverwith routing and static file serving
- Usage:
Launch the web server from the command line:
python -m build_tools.syllable_walk_web python -m build_tools.syllable_walk_web --port 9000 python -m build_tools.syllable_walk_web --output-base /path/to/output
Or programmatically:
>>> from build_tools.syllable_walk_web import run_server >>> run_server(port=8000)
Command-Line Interface
Launch the Pipe-Works Build Tools web application. Combines Pipeline (extraction/normalization/annotation) and Walker (dual-patch syllable walking, name generation) tools in a browser-based interface.
usage: python -m build_tools.syllable_walk_web [-h] [--port PORT] [--quiet]
[--output-base OUTPUT_BASE]
[--sessions-dir SESSIONS_DIR]
[--config CONFIG]
Named Arguments
- --port
Port to serve on. If not specified, automatically finds an available port (checks 8000-8099 first, then 8100-8999). Default: auto-detect
- --quiet
Suppress HTTP request logging. Default: False
Default:
False- --output-base
Base directory for pipeline run discovery. Default: _working/output
- --sessions-dir
Optional directory for saved walker sessions. Default: <output_base>/sessions
- --config
Path to INI config file. Reads the [build_tools] section for output_base, sessions_dir, corpus_dir_a, corpus_dir_b, port, and verbose. CLI arguments override INI values. Default: server.ini
Default:
'server.ini'
Examples:
# Launch on auto-detected port (default)
python -m build_tools.syllable_walk_web
# Launch on a specific port
python -m build_tools.syllable_walk_web --port 9000
# Launch in quiet mode (suppress HTTP request logs)
python -m build_tools.syllable_walk_web --quiet
# Use a custom config file
python -m build_tools.syllable_walk_web --config server.ini
Output Format
The web interface is an interactive browser-based tool with in-memory working state (pipeline job status, patch data, walks, candidates, selections).
It produces file outputs in two places:
Pipeline runs in
<output_base>/<timestamp>_<extractor>/(extract/normalize/annotate/db outputs)Package builds from the Walker tab:
Browser download:
<name>-<version>.zip(HTTP response from/api/walker/package)Disk persistence (best-effort):
<output_base>/packages/<name>-<version>_<timestamp>.zipplus<name>-<version>_<timestamp>_metadata.json
Interface Components:
Pipeline tab — Run the full extraction pipeline from the browser:
Filesystem browser for source directory/file selection
Extractor selection (Pyphen or NLTK), pyphen language selection
Live monitor for stage progress and subprocess logs
Run history view backed by manifest-discovered run directories (refreshes on tab entry and after run completion)
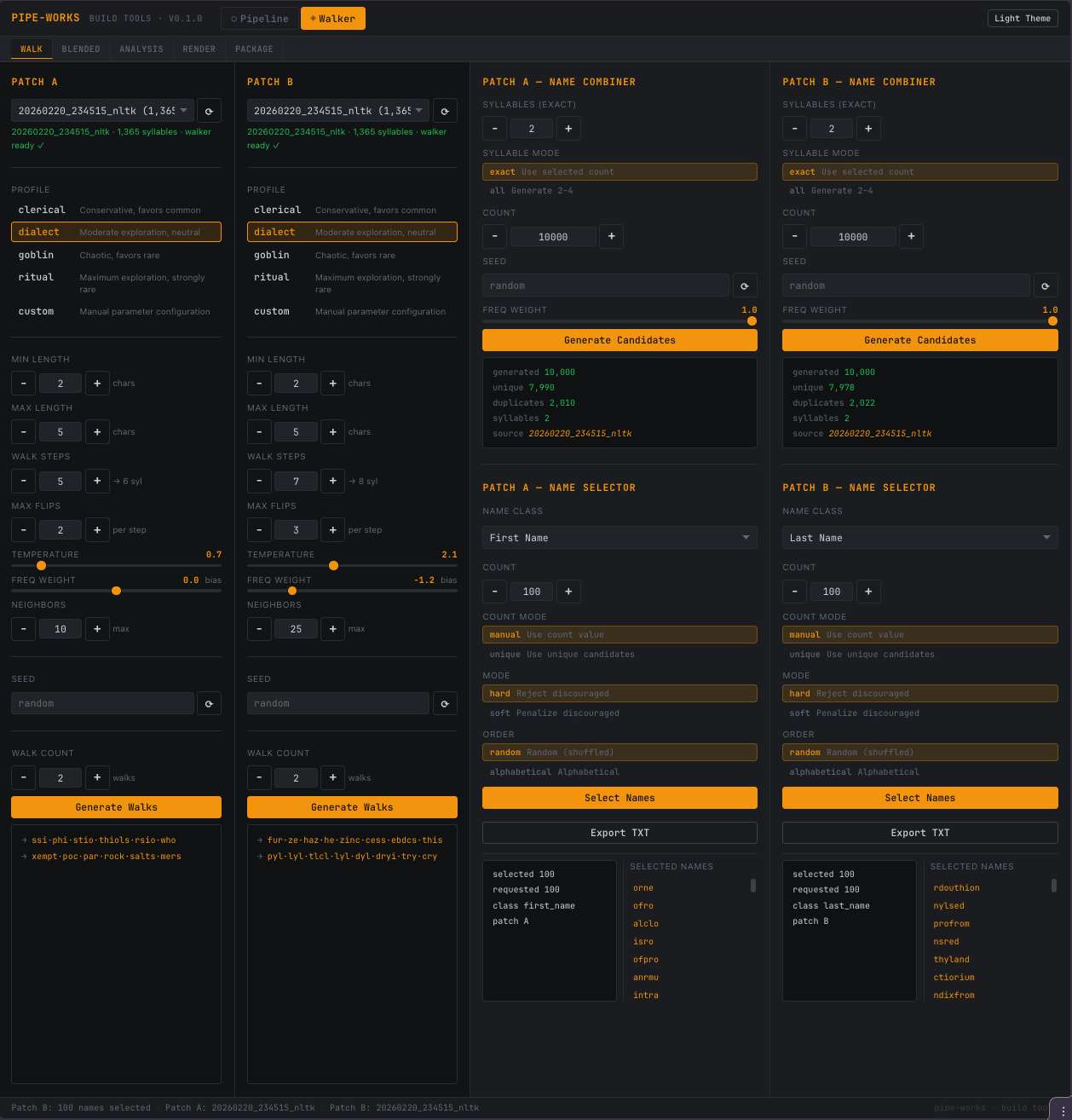
Walker tab — Dual-patch corpus exploration and name generation:
Load corpora into Patch A and Patch B for side-by-side comparison
Generate syllable walks with named profiles or custom walk parameters
Combine syllables into candidates in flat-sampling or walk-based mode
Select names by policy (first_name, last_name, place_name, etc.)
Reach deep-dive per profile (top reachable syllables with export)
Export selected names as text or build ZIP packages with manifest
Integration Guide
The web interface can run the full pipeline internally, so you can start from raw text without running CLI tools first.
Quickest path — start from scratch:
# Launch the web interface
python -m build_tools.syllable_walk_web
# In the browser:
# 1. Pipeline tab → browse to your source text → Start Pipeline
# 2. Walker tab → load the completed run into a patch → Walk / Combine / Select
Starting from existing pipeline output:
# If you already have pipeline runs in _working/output/
python -m build_tools.syllable_walk_web
# The Walker tab discovers runs automatically and lists them for loading
Custom output directory:
python -m build_tools.syllable_walk_web --output-base /path/to/corpus/output
INI configuration (``–config``):
The CLI reads [build_tools] settings from an INI file (default: server.ini).
CLI arguments override INI values.
[build_tools]
output_base = _working/output
corpus_dir_a = /path/to/patch_a/runs
corpus_dir_b = /path/to/patch_b/runs
port = 8000
verbose = true
When to use this tool:
To run the full extraction pipeline without memorizing CLI arguments
To compare two corpora side-by-side (dual-patch mode)
To interactively explore syllable walks through a browser
To generate, filter, and export names in a single session
To build ZIP packages with manifest metadata for downstream consumption
Advanced Topics
Architecture
The module is organised into backend API, backend services, frontend modules, discovery/state, and server wiring:
Backend API handlers (api/):
browse.py— Filesystem directory listingpipeline.py— Pipeline start/status/cancel endpointswalker.py— Thin compatibility wrapper layer (route-level entrypoints)walker_common.py— Shared validation/normalization helperswalker_lock.py— Active session lock enforcement helperswalker_session.py— Session save/list/load and run-state restore handlerswalker_cache_lock.py— Reach-cache rebuild + lock heartbeat/release handlerswalker_ops.py— Walk/combine/reach/select/export/package/analysis handlerswalker_types.py— TypedDict response contracts for extracted walker handler modules
Backend service modules (services/):
corpus_loader.py— Delegates tosyllable_walk.db.load_syllablescombiner_runner.py— Delegates toname_combiner.combinerselector_runner.py— Policy caching and delegation toname_selectorwalk_generator.py— Walk generation with profile routing and seed offsetsmetrics.py— Corpus shape metrics with length bucketing and terrain scorespackager.py— ZIP archive building with manifest and disk persistencepipeline_runner.py— Background subprocess execution with cancellationpipeline_manifest.py— Manifest IPC verification helpersprofile_reaches_cache.py— Reach profile cache read/write/verify helperswalker_run_state_store.py— Authoritative run-local IPC sidecars for patch outputswalker_session_store.py— Session artifact save/list/load/verify with lineage metadatawalker_session_lock.py— Cooperative single-user multi-tab lock leases (UX integrity)session_paths.py— Runtime resolution of sessions base and session file paths
Frontend modules (static/js/walker/):
corpus.js— Orchestrator for Walk tab corpus/session behaviorcorpus-api.js— Fetch wrappers for walker/session endpointscorpus-state.js— In-memory UI state modelcorpus-render.js— Hash/verification/rebuild/compare visual renderingcorpus-tooltips.js— Integrity/lock badge helpers and modal contentcorpus-actions-session.js— Save/load/repair/takeover/release session actionscorpus-actions-cache.js— Rebuild reach-cache action wiringcorpus-contracts.js— Shared JSDoc typedef contracts for frontend payloadscontrols.js/reach.js/operations.js— Walk, reach, combine/select/package controls and endpoint operations
Discovery and state:
run_discovery.py— Manifest-driven run discovery, selection discovery, and History payload shaping (status, timings, stage state, IPC hashes)state.py—PatchState,PipelineJobState, andServerState
Server (server.py):
stdlib
http.server.ThreadingHTTPServerfor concurrent XHRStatic file serving with directory-traversal guard
Route dispatch into API modules
Lazy API imports to avoid circular dependencies
Run Discovery
The server scans a base directory for run folders matching:
YYYYMMDD_HHMMSS_{extractor}.
GET /api/pipeline/runsusesoutput_baseby default.GET /api/pipeline/runs?patch=aand?patch=busecorpus_dir_a/corpus_dir_bwhen configured.
Discovery is strict and manifest-first:
Run folders must contain
manifest.json.manifest.jsonmust include required keys andrun_idmust match folder name.Missing/corrupt/non-conformant manifests are skipped (no legacy fallback parsing).
For each valid run, discovery reports:
folder/run id and extractor type
status and run timestamps
stage status map (extract/normalize/annotate/database)
manifest-derived metrics (including syllable count and processed-file count)
artifact paths (including
corpus_db_path/ annotated JSON when present)IPC hashes (input/output) from manifest
selection file map by name class
Pipeline Execution Model
Pipeline execution runs in a background thread via services/pipeline_runner.py.
Stages are subprocess-backed and logged line-by-line to job state:
extract(always)normalize(ifrun_normalize=True)annotate(ifrun_annotate=Trueand normalize ran)database(runs after annotate; executesbuild_tools.corpus_sqlite_builder --force)
Status is polled through GET /api/pipeline/status and includes:
status, current_stage, progress_percent, output_path, and structured log lines.
Corpus Loading and Walker Readiness
POST /api/walker/load-corpus performs two phases:
Synchronous data load: uses
services/corpus_loader.load_corpus, which delegates tobuild_tools.syllable_walk.db.load_syllables(SQLite preferred, JSON fallback).Background walker init: builds
SyllableWalkerand resolves profile reaches via run-local IPC cache.
Profile reach caching is run-directory local:
Cache path:
<run_dir>/ipc/walker_profile_reaches.v1.jsonCache schema:
build_tools/syllable_walk_web/schemas/walker_profile_reaches.v1.schema.jsonCache key material: - manifest IPC output hash (from
<run_dir>/manifest.json) - walker graph settings (neighbor distance, inertia, feature costs) - reach settings (threshold + named profile parameters)On cache hit, precomputed reaches are loaded.
On miss/invalid cache, reaches are recomputed and cache is rewritten.
The frontend polls GET /api/walker/stats until walker_ready=true. During load,
loading_stage reports phase progress (e.g., building neighbor graph).
The stats payload also includes reach_cache_status per patch
(hit | miss | invalid | error | none) to make cache
behavior explicit in diagnostics.
Important readiness guarantees:
Reach precomputation completes before
walker_readyis settrue.loader_statusandloading_errorexpose terminal failure states explicitly.Load concurrency is guarded by per-patch generation tokens, so stale background threads cannot overwrite newer corpus loads.
Candidate Generation Modes
POST /api/walker/combine supports two modes:
Flat sampling (default;
profileabsent or"flat"): delegates toname_combiner.combine_syllableswithfrequency_weight.Walk-based sampling (named profile or
"custom"): generates walks first, then aggregates features from walked syllables.
The response includes generated, unique, and duplicates counts.
Dual-Patch Comparison
The Walker tab supports loading two independent corpora into Patch A and Patch B. Each patch maintains its own:
Annotated syllable data and frequency map
Walker instance (with pre-computed neighbor graph)
Generated walks, candidates, and selections
This enables side-by-side comparison of different extractors, languages, or source texts.
Walker State Model
GET /api/walker/stats returns independent status for patch_a and patch_b.
Each patch reports loader_status plus readiness/error metadata.
|
Meaning |
|---|---|
|
No active load thread. Patch may be empty, or may have prior corpus metadata without a currently running initialization. |
|
Corpus load generation is in progress. |
|
Walker and pre-computed reaches are available; |
|
Current load generation failed. |
Response fields per patch include:
corpus(activerun_id)corpus_type(nltkorpyphen)syllable_countwalker_ready,loading_stage,loading_error,loader_statushas_walks,has_candidates,has_selectionsreaches(when available; includes reach count and computation timing)
Patch Isolation and Race Safety
Patch A and Patch B are fully isolated in server state.
Loading a corpus resets only the target patch state.
Walks/candidates/selections from one patch never overwrite the other patch.
Loader concurrency is generation-token guarded:
each
load-corpusincrementsload_generation;background init writes are applied only if generation is still current;
stale loader threads exit without mutating patch state.
This prevents rapid corpus switches from producing stale overwrite races.
Determinism and Seed Behavior
Walk generation is deterministic for fixed request parameters and seed.
Batched walks use
seed + iper walk to keep outputs deterministic while still varying entries within one request.Flat combiner and selector paths accept explicit seed values for deterministic output ordering/sampling.
Without a seed, behavior remains valid but non-deterministic between runs.
API Endpoints
Endpoint |
Method |
Description |
|---|---|---|
|
GET |
List discovered runs; supports |
|
GET |
Get pipeline job status, progress, and log lines |
|
POST |
Start extraction pipeline (source path, extractor, and optional stage/constraint fields) |
|
POST |
Cancel a running pipeline job |
|
POST |
Browse a filesystem directory (for source/output selection) |
|
GET |
Get dual-patch state (loaded corpora, loader/cache status, readiness, reach metadata) |
|
GET |
Corpus shape metrics for a patch (terrain scores, distributions) |
|
GET |
List available name class policies from |
|
POST |
Load a run’s corpus into a patch (builds walker in background) |
|
GET |
List saved dual-patch sessions with verification and lock metadata |
|
POST |
Persist current patch assignments as one immutable session revision |
|
POST |
Load one saved session, verify references, restore trusted sidecars |
|
POST |
Generate syllable walks with validated constraints and optional seed |
|
POST |
Generate candidates (flat mode or walk-based mode), returns deduplication stats |
|
POST |
Return top reachable syllables for one profile/patch (reach deep-dive tables) |
|
POST |
Select names by policy (name class, mode, count) |
|
POST |
Export selected names as a list |
|
POST |
Build ZIP archive with manifest (binary response) and persist package files to disk |
|
POST |
Recompute and rewrite reach-cache IPC artifact for one loaded patch |
|
POST |
Refresh active session lock lease for one holder |
|
POST |
Release active session lock lease for one holder |
|
GET |
Get current server settings (resolved |
|
POST |
Update the output base directory |
|
GET |
Return package version for UI header display |
The web server uses Python’s standard library http.server (no Flask dependency).
Common Request Fields
Key request bodies for current API routes:
For mutating Walker endpoints (
load-corpus,walk,combine,select,package,rebuild-reach-cache), includelock_holder_idwhen operating against an actively locked session.
Endpoint |
Important request fields |
|---|---|
|
|
|
|
|
optional |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Walker Endpoint Contract Details
Endpoint |
Contract and validation rules |
Success payload highlights |
|---|---|---|
|
No request body. Returns state for both patches, including |
|
|
Requires |
|
|
No request body. Lists saved session artifacts ordered newest-first. Includes verification, lineage, and lock metadata. |
|
|
Saves current patch references as session IPC artifact.
|
|
|
Requires |
Per-patch |
|
Requires ready walker for target patch. Validates numeric fields:
|
|
|
Requires loaded corpus. |
|
|
Requires precomputed reaches and valid |
|
|
Requires existing candidates. Validates patch and delegates policy validation to
selector service (unknown name class returns error).
If active session lock is set, requires matching |
|
|
Requires prior selection output for target patch. |
|
|
Accepts package metadata and include flags. Builds ZIP from in-memory state.
If active session lock is set, requires matching |
Binary ZIP response with attachment filename |
|
Requires loaded walker and patch context. Optional |
|
|
Requires |
|
|
Requires |
|
Pipeline Configure ↔ API Mapping
The Pipeline Configure tab now maps directly to POST /api/pipeline/start:
Configure control |
Request field / behavior |
|---|---|
Source picker (directory or file) |
|
Output picker |
|
Extractor ( |
|
Language radios + custom language code |
|
File pattern |
|
Min / Max syllable length |
|
Normalize toggle |
|
Annotate toggle |
|
Pipeline Output ↔ API Mapping
Monitor and History views consume pipeline API responses as follows:
UI output area |
API field(s) used |
|---|---|
Monitor status/progress/log |
|
Monitor completion message |
|
Monitor stage chips |
|
History run list |
|
History run detail metadata |
|
History output tree |
|
History database stage chip |
|
History stage chips (all stages) |
|
History IPC hash fields |
|
Walker Controls ↔ API Mapping
Walk, Combine, and Select controls map to Walker endpoints as follows.
Walker control |
API field |
Runtime effect |
|---|---|---|
Patch selector (A/B context) |
|
Routes request to isolated patch state. |
Walk count / steps |
|
Sets number of generated walks and walk length. |
Walk profile cards |
|
Named profile uses tuned walker profile path;
|
Walk max flips / temperature / frequency |
|
Controls walker transition behavior in custom mode. |
Walk neighbors |
|
Limits candidate neighbors evaluated per step. |
Walk min/max length |
|
Constrains syllable-length eligibility for starts/transitions. |
Walk seed |
|
Enables deterministic walk batches (internally offset per walk). |
Combine profile cards |
|
Chooses flat combiner mode vs walk-based generation mode. |
Combine count/syllables/seed |
|
Controls candidate volume, name length classes, and deterministic sampling. |
Selector class dropdown |
|
Applies selected policy from |
Selector mode/order/count/seed |
|
Controls strictness, output ordering, and deterministic random ordering. |
History Manifest Contract
History discovery is strict manifest-first (no legacy fallback parsing):
Run directory must contain
manifest.json.Manifest must include required contract keys:
manifest_version,run_id,status,extractor,config,metrics,stages,artifacts.run_idmust match the run directory name.Missing/corrupt/non-conformant manifests are skipped by discovery.
This keeps the run directory as the single source of truth and avoids cross-file drift between legacy metadata files and API payloads.
Pipeline Manifest and IPC
Each pipeline run writes <run_dir>/manifest.json as the canonical run record.
High-value fields used by History and diagnostics:
statuspluscreated_at_utc/completed_at_utcconfigandmetrics(includingfiles_processedand unique syllable count)stages(per-stage status and duration)artifacts(deterministic run output inventory)ipcblock:input_hashfrom canonical run configurationoutput_hashfrom canonical artifact+metric payloadlibrary metadata (version/ref) for provenance
Patch A/B Session IPC, Locks, and Rebuild Semantics
Session and patch restoration now use authoritative IPC artifacts:
Run-level state artifact:
<run_dir>/ipc/walker_run_state.v1.json
Patch output sidecars (written and verified per run):
<run_dir>/ipc/patch_a_walks.v1.json<run_dir>/ipc/patch_a_candidates.v1.json<run_dir>/ipc/patch_a_selections.v1.json<run_dir>/ipc/patch_a_package.v1.jsonsame pattern for Patch B (
patch_b_*)
Session artifact (runtime sessions base, not hardcoded to
_working):<sessions_base>/<session_id>.jsonsessions_baseresolves from explicit config override or defaults to<output_base>/sessions
Session lineage fields:
root_session_id: immutable origin session idparent_session_id: immediate source session id for repaired revisionsrevision: integer revision counter (original is0)
Verification status semantics (API authority):
verified: all relevant IPC links/hashes are valid and trustedmismatch: artifact exists but linkage/hash verification failedmissing: artifact or required hash fields are absenterror: parse/read/validation/internal failure
Stale session recovery vs repair:
Recovery on load-session is intentionally narrow: hash-drift mismatch can be loaded for continuity if the raw payload is readable.
Recovery does not auto-upgrade trust. The result remains integrity-signaled (stale/mismatch) until repaired.
Repair creates a new immutable revision (new
session_idwith lineage) and preserves prior artifact history.
Cooperative lock model:
Endpoints:
POST /api/walker/session-lock/heartbeatPOST /api/walker/session-lock/release
Lock lease TTL is currently 45 seconds and refreshed by heartbeat.
load-sessionacquires lock withlock_holder_idand optionalforce_lock(take-over flow).Mutating endpoints enforce active session lock ownership.
This is an integrity/UX coordination mechanism for single-user multi-tab use, not a security or authorization boundary.
Patch comparison and rebuild policy decisions:
GET /api/walker/statsexposes:patch_comparison.corpus_hash_relation:same|different|unknownpatch_comparison.policy: currentlywarn|none
Current product policy keeps compare mode as warn-only/no-policy (no
blockmode yet).POST /api/walker/rebuild-reach-cacheis already an explicit rebuild action. We intentionally do not expose a separate force/invalidate mode at this stage.
Manual QA Checklist (Phase 5)
Use this checklist when validating Walker session IPC behavior:
Two-tab lock conflict:
Load same session in tab A and tab B with different holders.
Confirm tab B shows lock conflict and cannot mutate without take-over.
Take over in tab B and confirm tab A heartbeats/release reflect loss of ownership.
Stale recovery and immutable repair:
Create a stale-session condition (hash drift), then load session.
Confirm load is continuity-tolerant but explicitly marked stale/mismatch.
Run repair and verify new
session_idwith incremented lineage revision.Confirm original session artifact remains unchanged.
Rebuild reach-cache states:
Trigger rebuild and verify transition through guidance states (for example rebuilding -> rebuilt/verified).
Validate status handling for
verified,recommended,missing,error.Confirm IPC hashes update after successful rebuild.
Session list and detail integrity:
Verify
GET /api/walker/sessionsshows verification, lineage, and lock metadata.Confirm UI labels and run detail reflect backend verification outputs exactly.
Regression safety:
Validate walk/combine/select/package flows still work when session features are unused.
Validate pipeline tab behavior is unchanged.
Notes
Dependencies:
Uses standard library
http.serverfor the web interface (no Flask)Uses
subprocessfor pipeline stage executionRequires NumPy for efficient feature matrix operations (build-time dependency)
Troubleshooting:
Port Already in Use:
The server auto-discovers available ports starting at 8000. If a specific port is requested
with --port and is unavailable, the server will fail with an error message.
# Auto-discover (tries 8000, 8001, 8002, ...)
python -m build_tools.syllable_walk_web
# Specific port (fails if unavailable)
python -m build_tools.syllable_walk_web --port 9000
No Runs Found:
If no runs are discovered in the Walker tab, ensure you have pipeline output directories
in the configured output base, or use the Pipeline tab to run an extraction first.
If patch-specific run roots are configured (corpus_dir_a / corpus_dir_b),
verify those paths contain timestamped run directories with valid manifest.json files.
# Check for existing runs
ls _working/output/
# Or run the pipeline from the web UI's Pipeline tab
Walker Load Fails or Stalls:
Use GET /api/walker/stats as the source of truth:
If
loader_status="loading", inspectloading_stagefor current phase.If
loader_status="error", inspectloading_errorand retry load.walker_ready=truemeans walks/reaches are ready for that patch.
Common causes:
Run directory missing required artifacts (manifest declares missing files)
Corrupt/unreadable SQLite/JSON artifacts
Incompatible or malformed run directory copied into output roots
Rapid Corpus Switching (Race-Safe Behavior):
Loading a new run while a previous load is in progress is supported. The server uses per-patch load generations and accepts writes only from the current generation. Older background loads are ignored, preventing stale state from overwriting the newly selected corpus.
If you switch repeatedly:
trust the latest selected run in the UI;
use
/api/walker/statsto confirm finalcorpusandloader_status.
Name Class Dropdown Empty or Unexpected:
Selector classes come from GET /api/walker/name-classes. If the dropdown
is empty or stale:
verify API route availability and server health;
verify
data/name_classes.ymlexists and is valid YAML;reload the page after fixing policy file issues.
Package Persistence Warnings:
The package endpoint always returns a ZIP download when package generation succeeds.
Disk persistence to <output_base>/packages/ is best-effort; permission/path issues
are logged as warnings on the server side and do not block the download.
Build-time tool:
This is a build-time analysis tool only - not used during runtime name generation.
Related Documentation:
Syllable Walker - Core syllable walker algorithm and CLI
Syllable Walker TUI - Interactive TUI for exploring phonetic space
Pipeline TUI - Interactive TUI for running extraction pipelines
Syllable Feature Annotator - Generates input data with phonetic features
Corpus SQLite Builder - Builds SQLite database for fast loading
Name Combiner - Generates name candidates
Name Selector - Selects names by policy
API Reference
Pipe-Works Build Tools — Web Application
Combined web interface for the Pipeline and Walker build tools,
providing a browser-based alternative to pipeline_tui and
syllable_walk_tui.
This is a build-time tool only — not used during runtime name generation.
- Features:
Pipeline tool: extraction, normalization, annotation with live monitoring
Walker tool: dual-patch syllable walking, name combiner, name selector
Corpus analysis with terrain visualization and profile reach deep-dives
Name rendering and package export (ZIP with manifest + disk metadata persistence)
Dark/light theme support
18 API endpoints across Pipeline, Walker, Browse, Settings, and Version groups
- Architecture:
api/: Request handlers (browse,pipeline,walker)services/: Business logic (corpus_loader,combiner_runner,selector_runner,walk_generator,metrics,packager,pipeline_runner)state.py: Dataclasses (PatchState,PipelineJobState,ServerState)server.py: stdlibhttp.serverwith routing and static file serving
- Usage:
Launch the web server from the command line:
python -m build_tools.syllable_walk_web python -m build_tools.syllable_walk_web --port 9000 python -m build_tools.syllable_walk_web --output-base /path/to/output
Or programmatically:
>>> from build_tools.syllable_walk_web import run_server >>> run_server(port=8000)
- class build_tools.syllable_walk_web.CorpusBuilderHandler(request, client_address, server)[source]
Bases:
BaseHTTPRequestHandlerHTTP request handler for the Corpus Builder web app.
Serves static files from the
static/directory and routes/api/*requests to the appropriate handlers.- server_version = 'PipeWorksCorpusBuilder/0.1'
-
state:
ServerState= ServerState(patch_a=PatchState(run_id=None, corpus_type=None, corpus_dir=None, syllable_count=0, walker=None, walker_ready=False, loading_stage=None, load_generation=0, active_load_generation=None, loading_error=None, manifest_ipc_input_hash=None, manifest_ipc_output_hash=None, manifest_ipc_verification_status=None, manifest_ipc_verification_reason=None, reach_cache_status=None, reach_cache_ipc_input_hash=None, reach_cache_ipc_output_hash=None, reach_cache_ipc_verification_status=None, reach_cache_ipc_verification_reason=None, profile_reaches=None, annotated_data=None, frequencies=None, walks=[], candidates=None, candidates_path=None, selections_path=None, selected_names=[]), patch_b=PatchState(run_id=None, corpus_type=None, corpus_dir=None, syllable_count=0, walker=None, walker_ready=False, loading_stage=None, load_generation=0, active_load_generation=None, loading_error=None, manifest_ipc_input_hash=None, manifest_ipc_output_hash=None, manifest_ipc_verification_status=None, manifest_ipc_verification_reason=None, reach_cache_status=None, reach_cache_ipc_input_hash=None, reach_cache_ipc_output_hash=None, reach_cache_ipc_verification_status=None, reach_cache_ipc_verification_reason=None, profile_reaches=None, annotated_data=None, frequencies=None, walks=[], candidates=None, candidates_path=None, selections_path=None, selected_names=[]), pipeline_job=PipelineJobState(job_id=None, status='idle', config=None, current_stage=None, progress_percent=0, log_lines=[], output_path=None, error_message=None, process=None), output_base=PosixPath('_working/output'), sessions_base=None, corpus_dir_a=None, corpus_dir_b=None, walker_session_locks={}, walker_session_locks_guard=<unlocked _thread.lock object>, active_session_id=None, active_session_lock_holder_id=None)
- build_tools.syllable_walk_web.find_available_port(start=8000, max_tries=100)[source]
Find an available port starting from start.
Tries ports
startthroughstart + max_tries - 1. Returns the first available port, orNoneif none found.
- build_tools.syllable_walk_web.run_server(port=None, verbose=True, output_base=None, sessions_dir=None, corpus_dir_a=None, corpus_dir_b=None)[source]
Start the HTTP server.
- Parameters:
port (
int|None) – Port to listen on. IfNone, checks 8000-8099 first, then 8100-8999.verbose (
bool) – IfTrue, log HTTP requests to stderr.output_base (
Path|None) – Base path for pipeline run discovery. Defaults to_working/output.sessions_dir (
Path|None) – Optional explicit directory for saved walker sessions. Defaults toNone(callers deriveoutput_base/sessions).corpus_dir_a (
str|None) – Run discovery directory for Patch A.corpus_dir_b (
str|None) – Run discovery directory for Patch B.
- Returns:
0 for clean shutdown, 1 for error.
- Return type:
Exit code